8.4. The Bias-Variance Trade-off¶
An open question from the previous section is how to choose the value of the hyperparameter \(k\). To explore this, let’s return to the simplified churn data set, which only has 100 observations and two independent features (total_intl_charge and account_length).
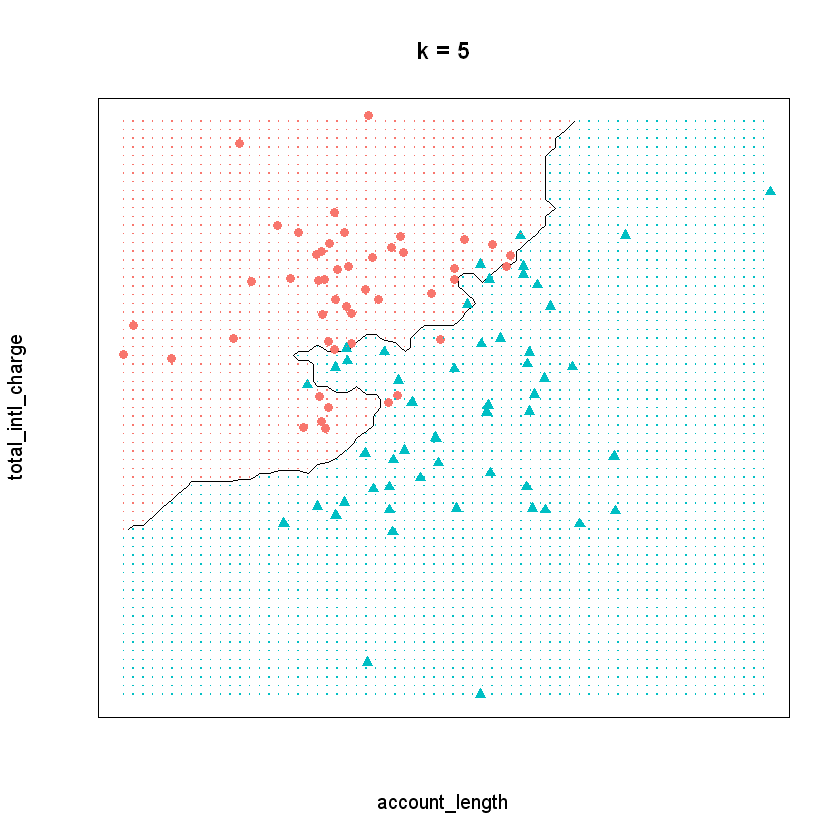
To visualize the kNN model when \(k\) equals five, we can plot the decision boundary of our model on this data, or the line that partitions the feature space into two classes. In the plot below, the area shaded in red represents points where a majority of the five nearest neighbors churned. Similarly, the area shaded in blue represents points where a majority of the five nearest neighbors did not churn. Therefore, this plot shows how our kNN model separates the data into two classes.
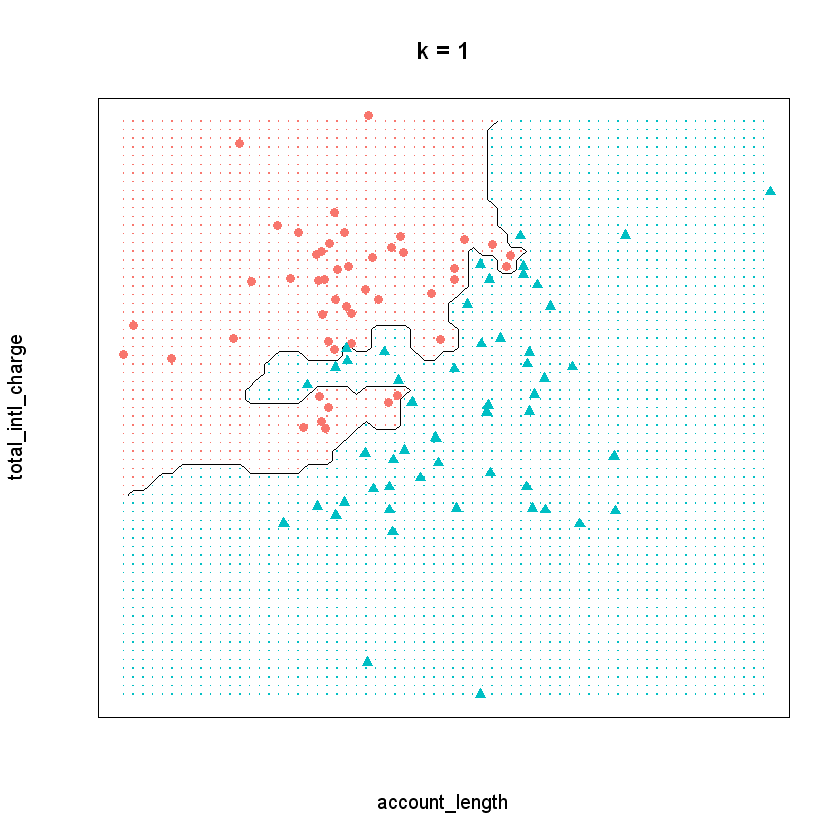
Now observe what happens if we run the model with a \(k\) of one instead. By decreasing the value of \(k\), we have increased the “sensitivity” of the model. In other words, the decision boundary now contorts itself so that every single point in the data set lies in the correct region; there is not a single misclassified observation. Compare that to the model when \(k\) equals five, where the decision boundary is less flexible and there are some observations in the wrong region.
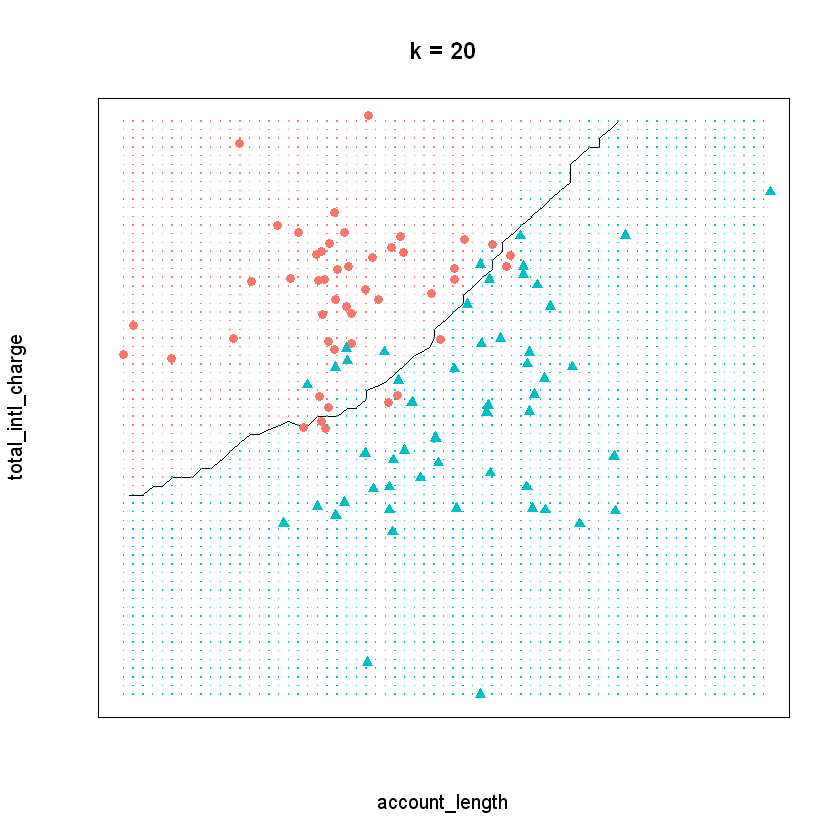
Finally, let’s see the decision boundary when we set \(k\) to twenty. Now the model seems much more inflexible - the boundary is almost a straight line and does not closely adhere to any individual point.
Which one of these scenarios is best? It may be tempting to assume that the best model is the one where \(k\) equals one. After all, this model provides the closest fit to the data. However, this is often not the case due to a principle known as the bias-variance trade-off. The bias-variance trade-off refers to the tension between how closely a model fits its training data, versus how well it generalizes to unseen data.
For the kNN algorithm, the closest fit is achieved when \(k\) equals one. The primary issue is that this fit is likely too close. When \(k\) is very low, the model may be so flexible that it starts to pick up on the random idiosyncrasies of the training data. Remember that we are building our model on a sample of data and the information that sample provides is a combination of signal and noise. The signal of the sample reflects the true, underlying relationships between the variables of interest. This information is generalizable to other observations not in our sample, and is therefore useful for building our predictive model. The noise of the sample refers to the random variation that is unique to the particular observations in the training data. When a model starts to fit the noise of a sample, we say that it is overfitting the data.
Access the web application below to further explore the overfitting and the bias-variance trade-off.
Ultimately we want our model to be flexible enough that it can pick up the signal in the sample, but not so flexible that it starts to pick up on the noise. This is the essence of the bias-variance trade-off. What, then, is the value of \(k\) that correctly balances this trade-off? Unfortunately, there is no single correct answer. The right value for \(k\) depends on the properties of the data set one is working with. Therefore, data scientists typically divide their data up into train and validation sets to test different values of \(k\), according to a variety of performance metrics. This process is described in the next chapter.