10. Model Evaluation¶
To build, compare, and evaluate different models, data scientists divide their data into several distinct sets. The work set (typically around 80% of the available data) is reserved to build, tune, and compare different models. Within the work set, 60% of the available data is designated as the training set, which is used to build different models, and 20% is designated as the validation set, which is used to compare those models. The final 20% of the data is reserved as a holdout set, which is reserved to evaluate the performance of the final model.
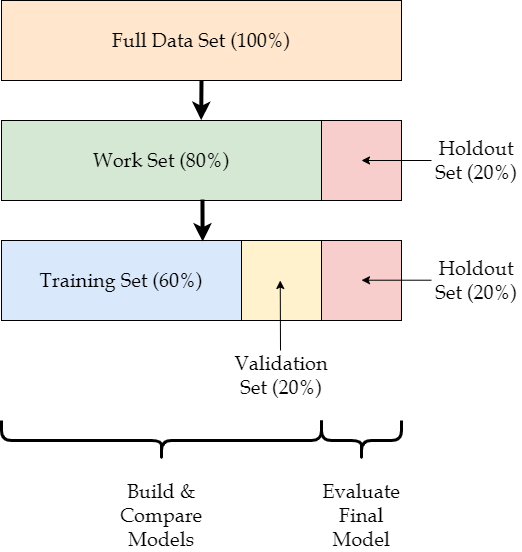
This process is described in more detail in the subsection Partitioning Data. The next subsection, Performance Metrics, describes some common metrics that data scientists use to compare and evaluate predictive models.