Decision Trees
Contents
9.1. Decision Trees¶
Classification and regression tree (CART) models are a popular class of machine learning algorithms that make predictions according to a set of logical rules learned from training data. Tree models that predict discrete outcomes are referred to as classification trees, while tree models that predict continuous outcomes are referred to as regression trees.
One major advantage of CART models is their interpretability. As we will see, CART models make predictions according to a series of logical rules that can be analyzed and understood by human users. This is in contrast to many other algorithms (like the random forest model discussed in the next section), which are more difficult to interpret.
9.1.1. Classification Trees¶
For many businesses, customer churn is an important metric for measuring customer retention. Banks, social media platforms, telecommunication companies, etc. all need to monitor customer turnover to help understand why customers leave their platform, and whether there are intervention strategies that can help prevent customer churn. Imagine that you work for a telecommunications provider and would like to reduce customer churn. To that end, you hope to develop a predictive model that will identify which customers are at a high risk of leaving for another provider. If you could identify these customers before they leave, you may be able to develop intervention strategies that would encourage them to stay. Using historical customer data that your company collected in the past quarter, you compile a data set with the account characteristics of each customer and whether or not they “churned” by the end of the previous quarter. This data is stored in a data frame called churn, the first few rows of which are shown below. A data dictionary which describes each variable in the data set is also provided below.
| account_length | international_plan | voice_mail_plan | number_vmail_messages | total_day_minutes | total_day_calls | total_night_minutes | total_night_calls | total_intl_minutes | total_intl_calls | total_intl_charge | number_customer_service_calls | churn |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 165 | no | no | 0 | 209.4 | 67 | 150.2 | 88 | 12.8 | 1 | 3.46 | 0 | no |
| 103 | no | no | 0 | 180.2 | 134 | 181.7 | 134 | 8.4 | 3 | 2.27 | 1 | no |
| 90 | no | yes | 27 | 156.7 | 51 | 123.2 | 111 | 12.6 | 6 | 3.40 | 2 | no |
| 36 | no | no | 0 | 177.9 | 129 | 306.3 | 102 | 10.8 | 6 | 2.92 | 2 | no |
| 95 | no | yes | 35 | 229.1 | 143 | 248.4 | 110 | 3.9 | 3 | 1.05 | 0 | no |
| 119 | no | no | 0 | 231.5 | 82 | 211.0 | 118 | 7.4 | 10 | 2.00 | 1 | no |
account_length: number of months the customer has been with the provider.internation_plan: whether the customer has an international plan.voice_mail_plan: whether the customer has a voice mail plan.number_vmail_messages: number of voice-mail messages.total_day_minutes: total minutes of calls during the day.total_day_calls: total number of calls during the day.total_night_minutes: total minutes of calls during the night.total_night_calls: total number of calls during the night.total_intl_minutes: total minutes of international calls.total_intl_calls: total number of international calls.total_intl_charge: total charge on international calls.number_customer_service_calls: number of calls to customer service.churn: whether or not the customer churned.
To understand classification trees, let’s start with a simplified version of our churn data set that only has twelve observations and two independent features, total_intl_charge and account_length. Our feature space looks as follows:
Parsed with column specification:
cols(
account_length = col_double(),
total_intl_charge = col_double(),
churn = col_double()
)
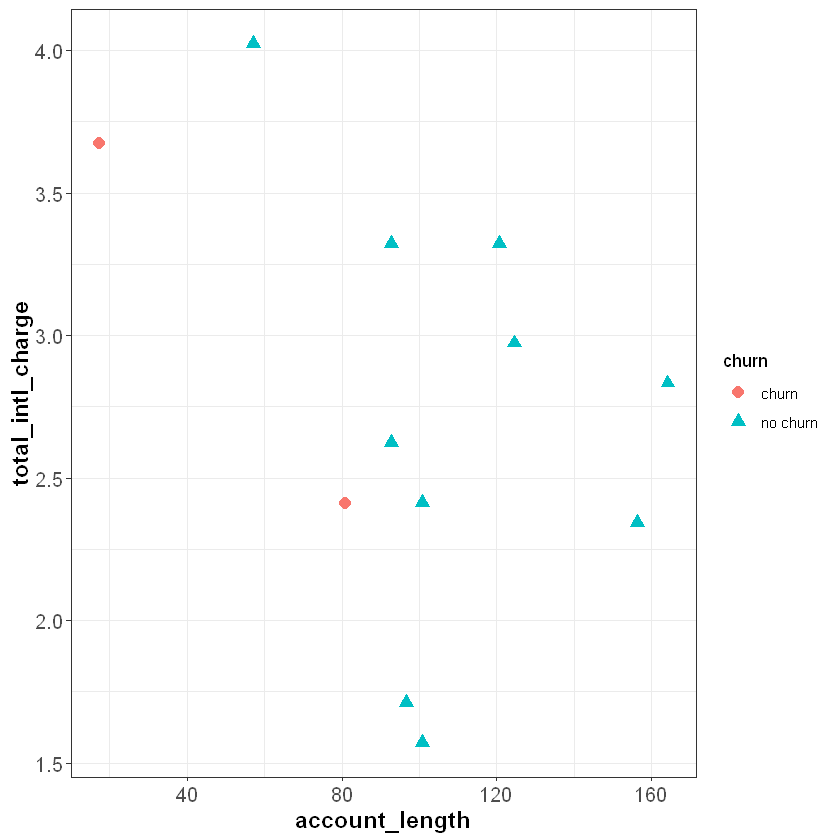
The classification tree algorithm works by drawing a straight line that partitions the feature space to maximize the homogeneity (or minimize the entropy) of each sub-region. For example, imagine we drew a vertical line at around account_length = 87, dividing the feature space into R1 and R2. Intuitively, R2 is completely homogeneous because it only contains observations with the same outcome—“no churn”. R1 is less homogeneous because it contains two “churn” observations and one “no churn” observation.
Parsed with column specification:
cols(
account_length = col_double(),
total_intl_charge = col_double(),
churn = col_double()
)
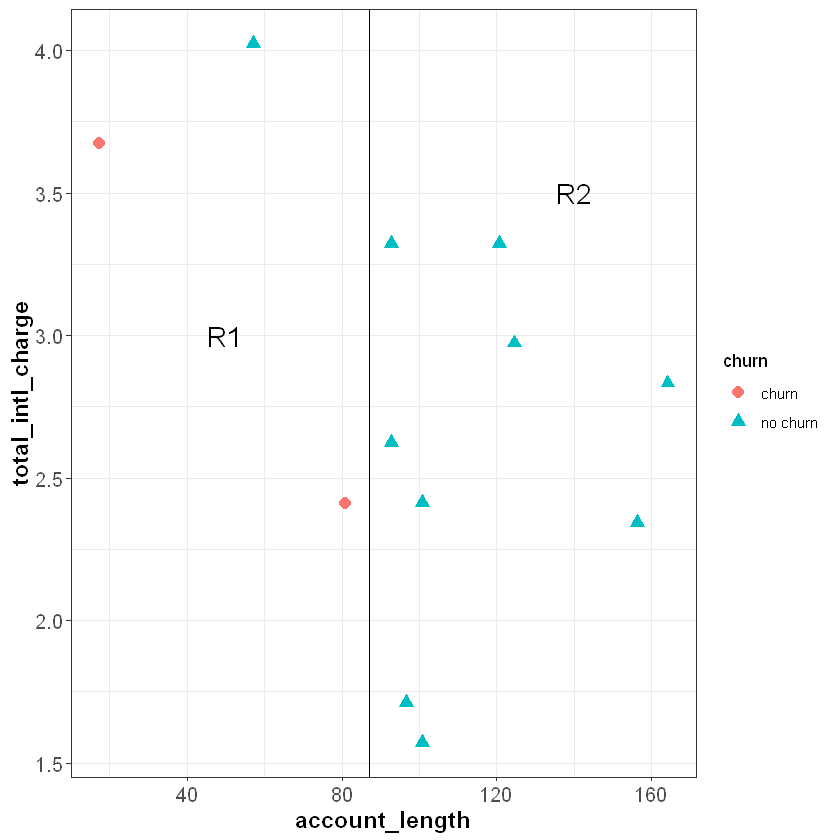
In this simple example we made cuts based on a visual inspection of the data, but the classification tree algorithm uses a measure known as entropy to ensure that each cut maximizes the homogeneity of the resulting subspaces. Entropy is defined as follows:
where the data set has \(C\) classes (or unique outcome values), and \(p_i\) represents the proportion of observations in the data from the \(i\)th class. In our case \(C=2\) because we have two classes: “churn” and “no churn”. Notice, this is very similar to the log loss formula that we introduced in Log Loss.
Using this formula, we can first calculate the entropy of our original data set (before we made any cuts), which we’ll call \(E_0\). There are two “churn” customers and ten “no churn” customers, so the entropy is:
Now we will calculate the entropy after making the cut, for each subspace separately. The subspace R2 is completely homogeneous (all nine customers are “no churn”), so the entropy equals zero:
The subspace \(R1\) has one “no churn” and two “churns”, so the entropy equals:
To calculate the overall entropy after making the cut at account_length = 87, we take a weighted average of \(E_{R1}\) and \(E_{R2}\) based on the number of observations in each subspace:
The information gain, or the reduction in entropy due to this cut, is then: $\(E_0 - E_{Cut1} = 0.1957 - 0.0691 = 0.1266\)$
Each cut is made at the point that will result in the greatest reduction in the information gain. To further reduce the entropy of R1, we can make a cut around total_intl_charge = 3.8 to partition R1 into two smaller regions (R3 and R4) that are completely homogeneous. Because the feature space is completely divided into pure regions, the entropy after the second cut is zero:
Parsed with column specification:
cols(
account_length = col_double(),
total_intl_charge = col_double(),
churn = col_double()
)
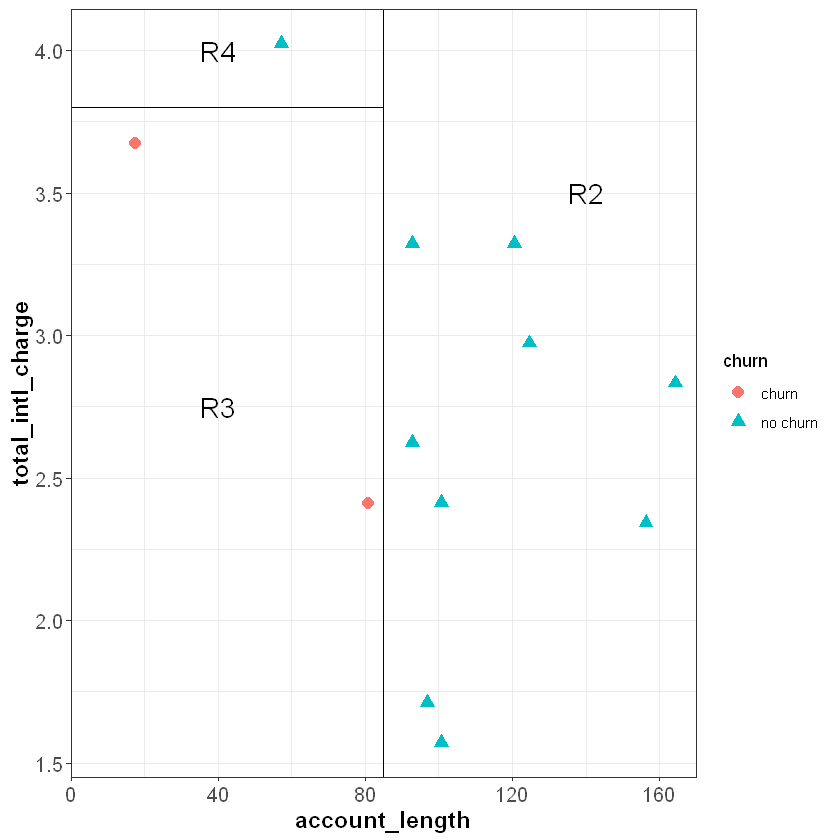
Because each subspace is completely pure, there are no additional cuts we could make to further reduce the entropy.
To create pure feature space, we first made a cut at account_length = 87, then within the region where account_length was less than 87 made an additional cut at total_intl_charge = 3.8. From this we can write out a set of decision rules:
We can use this decision tree to predict whether or not a new observation will churn. For example:
If a new observation has an
account_lengthgreater than or equal to 87, we move down the left branch of the tree and predict “no churn”.If a new observation has an
account_lengthless than 87 and atotal_intl_chargegreater than or equal to 3.8, we would move right at the first split and left at the second split of the tree, leading to a prediction of “no churn”.If a new observation has an
account_lengthless than 87 and atotal_intl_chargeless than 3.8, we would move right at the first split and right at the second split of the tree, leading to a prediction of “churn”.
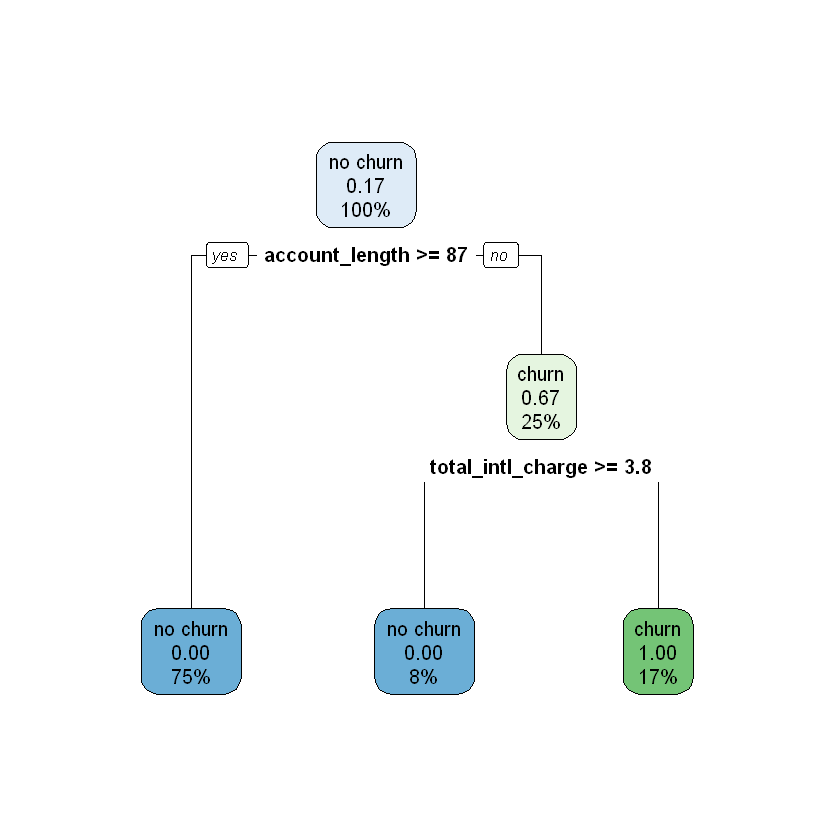
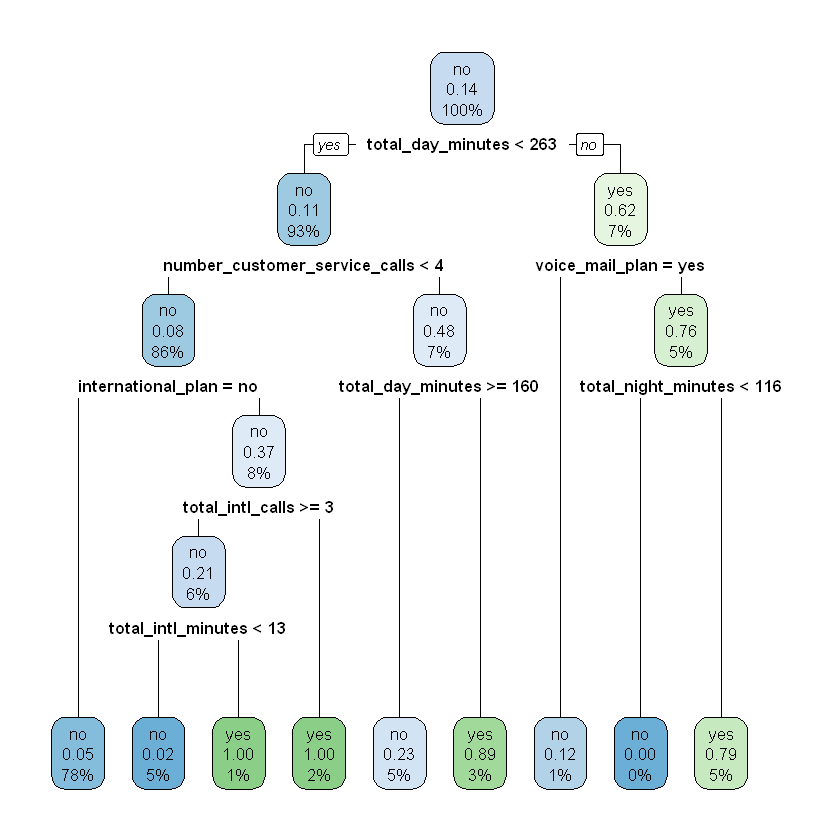
How do we interpret the numbers shown in the tree? In the plot each node has three rows, showing (in order):
The majority class in that node (“churn” / “no churn”).
The proportion of the observations in that node that churned.
The percentage of the total data inside that node.
For example, let’s start at the top node, which represents the data set before any cuts have been made. Because no cuts have been made, this node includes all of the data, so the third line shows 100%. Of the twelve observations in the data set, two of them churned, so the proportion of observations that churned equals (2 / 12) \(\approx\) 0.17. Because this proportion is lower than the default cutoff of 0.5, the majority class for this node is “no churn”.
Now imagine what happens as we work our way down the tree. If account_length is greater than or equal to 87 we move to the left branch. This corresponds to the subspace R2 in the plot of the feature space. This subspace contains nine observations, or 75% of the total observations in the data set ((9 / 12) = 75%). None of these observations churned, so the second line in the node is 0.00, and the majority class is “no churn”.
Now imagine we work our way down the right branch of the tree. If account_length is less than 87, we move into the subspace R1. R1 has three observations ((3 / 12) = 25%), two of which churned ((2 / 3) \(\approx\) 0.67). From this node, if total_intl_charge is less than 3.8 we move to the right, which represents subspace R3. Here we have two observations ((2 / 12) \(\approx\) 17%), both of which churned ((2 / 2) = 1.00). If instead total_intl_charge is greater than or equal to 3.8 we move to the left, which represents subspace R4. Here we have one observation ((1 / 12) \(\approx\) 8%), which did not churn ((0 / 1) = 0.00).
In R, we can fit a classification tree to our data using the rpart() function from the rpart package. This function uses the following syntax:
Syntax
rpart::rpart(y ~ x1 + x2 + ... + xp, data, maxdepth = 30)
Required arguments
y: The name of the dependent (\(Y\)) variable.x1,x2, …xp: The name of the first, second, and \(pth\) independent variables.data: The name of the data frame with they,x1,x2, andxpvariables.
Optional arguments
maxdepth: The maximum depth of the tree (see Tuning Hyperparameters below).
Then, after we have built a model with rpart(), we can visualize the tree with the rpart.plot() function from the rpart.plot package:
Syntax
rpart.plot::rpart.plot(x)
Required arguments
x: A tree model built withrpart().
Below we apply these functions to our full churn data set:
model <- rpart(churn ~ ., data = churn)
rpart.plot(model)
9.1.1.1. Tuning Hyperparameters¶
Let’s return to the simplified data set from the previous section, with only twelve observations and two features. After inspecting the classification tree we built from this data, you may suspect that something is wrong with the right branch - customers with a higher total_intl_charge are classified as “no churn”, while customers with a lower total_intl_charge are classified as “churn”. Based on the context of the business we may find this pattern surprising, as we expect customers with high international charges to be more likely to switch services. One possibility is that we are overfitting the data, so the decision tree is picking up on the noise in the sample instead of the signal.
To prevent overfitting, we can prune the decision tree to a certain depth; or, in other words, limit how many cuts we can perform. For example, let us prune this tree to a depth of one, meaning the algorithm cannot make more than one cut. The resulting pruned tree is shown below. Under this set of rules, customers with an account_length greater than or equal to 87 are classified as “no churn”; this is because subspace R2 (which represents account_length >= 87) contains only “no churn” observations. Customers with an account_length less than 87 are assigned a probability of churning of 0.67; this is because subspace R1 (which represents account_length < 87) contains two “churn” observations and one “no churn” observation ((2 / 3) \(\approx\) 0.67).
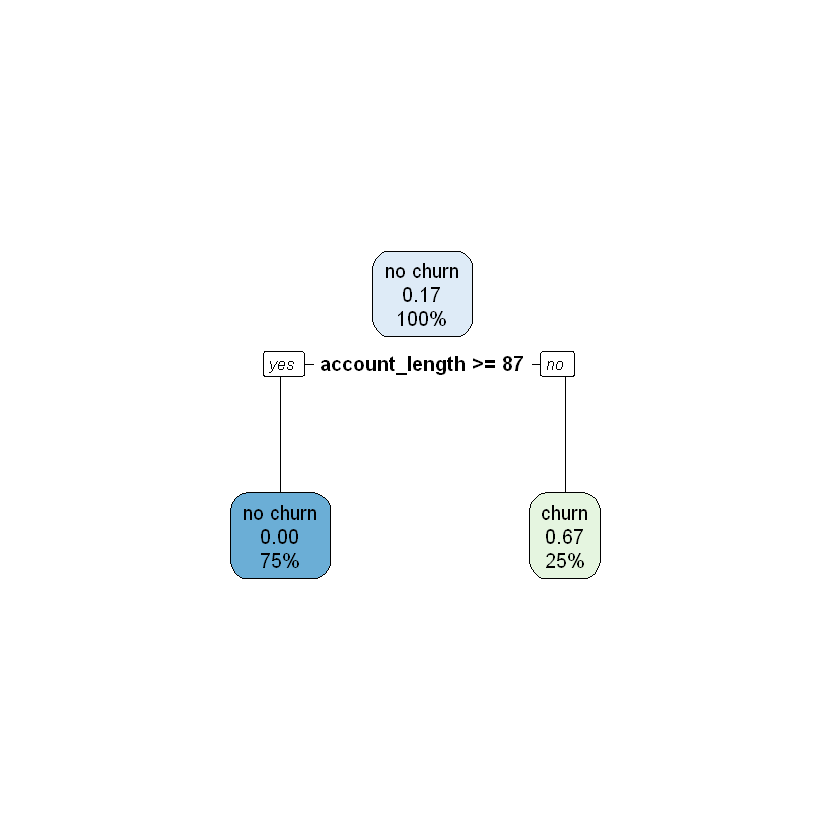
By tuning the value of the tree’s depth, we seek to balance the bias-variance tradeoff. The bias-variance tradeoff refers to the tension between how closely a model fits its training data, versus how well it generalizes to unseen data. For the decision tree algorithm, the closest fit to the training data is achieved when the tree is not pruned at all and can grow unconstrained. The primary issue is that this fit is likely too close. When the pruning depth is too large, our tree will grow too deep and overfit the training data. Conversely, if the depth is too small, our tree will not grow deep enough and will underfit the training data. Therefore, we need a method to identify the value of depth that balances this tradeoff on our data. This is covered in a subsequent section, Model Evaluation.
9.1.2. (§) Regression Trees¶
This section is optional, and will not be covered in the DSM course.
[In Progress]